Over the last several months I’ve been exploring an insurance use case for data sets, and I’ve had the following question in mind:
What would need to be in place, from an infrastructure point of view, to facilitate the creation of an insurance policy guarding against data loss?
I’ve introduced a theoretical, step-by-step description of this use case and proposed varoius roles that would be involved in the process:

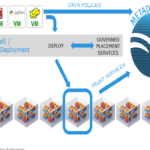
In stepping through this use case it is reasonable to assume that an insurer would expect to have governed access to an auditable dashboard for insured data sets. One data structure that would enable this functionality is called a Metadata Lake. This data structure groups two items together: (a) application data policies, and (b) the current level of trusted infrastructure hosting the application data.
Part of the insurance underwriting process is the establishment, by the insurer, of a risk profile. These trust inspections would attempt to answer the following questions:
- how well protected is the data set,
- what is the likelihood of loss, and
- how much financial risk would the insurer be taking on
As part of this process the insured would need mechanisms to evaluate the trusted infrastructure providing the data set’s current level of protection. I’ve discussed a potential trust taxonomy that can assist in that process. In many environments this would be a manual process that occurs with the assistance of somebody from IT that could run manual reports highlighting the level of trust. This is time consuming.
In place of this approach I’ve suggested an automated surfacing of trust dimension from the storage layer up to the cloud orchestration layer. The results, of course, would be placed in a Metadata Lake.
I’m also suggesting that the location of the data set on that infrastructure is recorded in the Metadata Lake. These two things, when tied together, provide for a much faster trust inspection and underwriting process. If these two things are not in place, it is reasonable to assume that an insurer would request that some form of Metadata Lake is implemented.
Once written, an insurance policy would likely specify the minimum level of protection that the data set would require in order for a claim to be submitted in the case of data loss. This introduces the need for some form of governed placement of application data. While in many cases the placement has already occurred, going forward the industry would need to be move toward automated and governed placement based on policy (e.g., for an insurance policy). In a previous post I’ve traced through the process of automation that would support such an environment. The Metadata Lake, through its maintenance of both application policy and trust taxonomy, plays a big role.

This brings us to the next step in the underwriting process: data valuation. This aspect of data set underwriting is probably the most interesting new piece of the puzzle and I will start diving into it in future posts. Before doing so I’d like to move through the rest of the underwriting process to more fully summarize the impact of data insurance on the infrastructure.
In my next post I will begin to look at facilitating post-insurance audits of data set compliance to insurance policies.
Steve
EMC Fellow