As I stated in my last post:
As the economic value of data rises, the need for it to be stored on trusted infrastructure rises as well.
This statement brings to mind a number of questions, including:
- How is the economic value of data calculated, initially and over time?
- How is that data mapped to the appropriate layer of trusted storage based on that value?
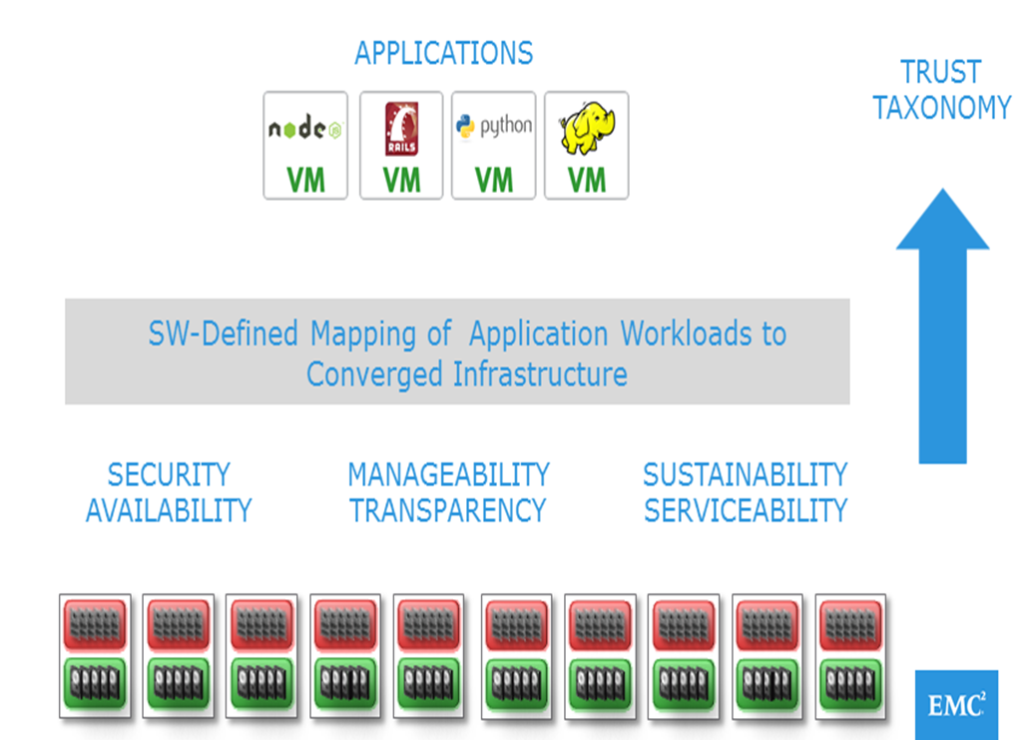
The diagram below is a helpful start in order to answer those questions. The storage infrastructure on which valuable data resides must begin to surface a more robust “trust taxonomy”.

This surfacing of a trust taxonomy is likely to occur via a set of software-defined storage APIs (e.g. EMC’s ViPR). Nikhil Sharma formally introduced the taxonomy in his Reflections blog post.
How then does the mapping of “valued data” to trusted infrastructure occur?
I’ve written before about the mapping of applications and data to a software-defined data center. Most of this thinking was based on application performance. Tools such as VMware have long had the ability to:
- Call a software API to discover the number of servers, CPUs, memory, etc., and perform a workload placement of the app onto the correct server (and monitor that placement over time).
- With the acquisition of Nicira several years ago, VMware now had a software API to discover the number of network switches, ports, allocated bandwidth, etc., and VMware could not only provision the correct server but also automatically provision the correct network path.
- With the advent of software-defined storage APIs, VMware can now call a storage API to discover the number of storage devices, their capabilities, amount allocated, etc. This is the final piece of the puzzle for full SDDC automation.
I like to use the video below to highlight this automation.
This model is performance-based. It uses mathematical modeling techniques to place workloads into the best-fit performance configuration.
For the data value conversation, however, the industry needs to start thinking about trust mappings. In other words, cloud management and orchestration stacks need to bubble up the trust characteristics (in the form of available cloud trust services) from all elements of the data center: servers, networks, and storage:

By using this approach the orchestration framework is bringing the trust taxonomy surfaced by the storage layer (as well as other data center components) closer to the application level.
In future posts I will discuss the required marriage of SDDC Trust Services and applications, especially in the context of data value.
Steve
EMC Fellow