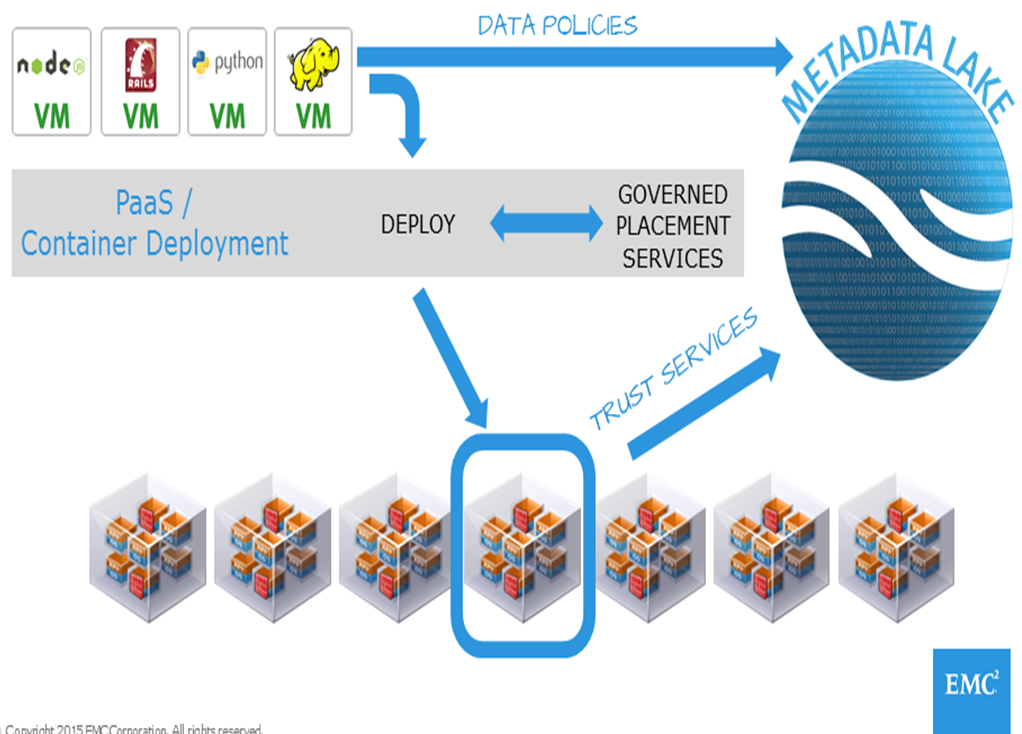
In a recent post I suggested that creating a new repository (Metadata Lake) can enable an architecture that supports data valuation (the process of assigning economic or business value to data). The creation of this repository, which contains both data policies and infrastructure mappings, can support specific use cases (such as data insurance).
I’ve been spending a lot of time discussing the data insurance use case because it is a clear example of assigning economic value to data. Insurance premiums would be paid based on assessed data value.
At this point everything I have suggested is greenfield. If there are no existing applications already deployed, a first step towards value-based deployment would look like this:
- Assess the economic value of an application data set (which I will describe in future posts)
- Assign business policies for the application based on value
- Store these policies in a Metadata Lake
The second step would involve the possible target infrastructures for the application data:
- Surface trust characteristics from a software-defined storage layer
- Report overall trust services from the SDDC layer
- Store these trust services, from all target clouds, into the same Metadata Lake.
Once the Metadata Lake contains both of these elements, an application deployment layer (e.g. a PaaS layer such as CloudFoundry) could leverage Governed Deployment Services to facilitate automated application mapping based on business value. The diagram below highlights this approach:

I have previously written an article describing the flow of this governed placement service model. I view this model as a foundational architecture for creating a data valuation ecosystem. Unfortunately, it is also a greenfield architecture because it requires modification up and down the stack (from the storage all the way up to the app deployment layer).
What is the journey that traditional data center operators would need to take in order to eventually reach the goal of a data valuation ecosystem?
In my opinion a value-based transformation of IT infrastructure would follow a similar path that the Journey to the Private Cloud provided for virtualizing IT environments. This journey was chronicled several years ago (I wrote about it here). The diagram below highlights the phases of this journey, which is primarily measured by the y-axis value: percent virtualized.

Is there an equivalent process that customers can leverage to move their data center towards an architecture which supports data valuation? In my opinion the answer is yes. Instead of focusing on “percent virtualized”, I believe that data center operators should focus on “percentage of applications inventoried”:

One place to start this transformation is via application decommissioning. This process involves (a) evaluating the current business value of applications, and (b) relocating the application (and the data) to a storage layer that possesses trust characteristics such as “compliant”, “archival”, and/or “searchable”.
I will explain this process in more detail in an upcoming post.
Steve
EMC Fellow