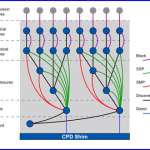
In the past few months I’ve been taking a look at varied applications workloads and their impact on the underlying IT infrastructure. The classic application workload, pictured on the left, generates content (blue) and metadata about that content (red), and stores them onto the IT infrastructure.

In my discussion about this topic I’ve been looking at this phenomena from a storage perspective (e.g. the evolution of object-based systems).
From the storage perspective I then moved up the stack to discuss the intersection of these systems with infrastructure-based data center applications (e.g. innovative backup and recovery algorithms that leverage object stores).
I’d like to take a look at the evolution of innovative techologies from the application’s perspective.
One of the richest areas to explore in this regard would be to take a deeper look at application creation of metadata. There are several important use cases that I believe are worth covering:
- Companies with large amounts of (disorganized) legacy content.
- Companies designing their entire business model around digital content.
- Increased regulatory audits on these companies.
In all of these cases, metadata is enormously helpful. Metadata can help content move through a business workflow. It can help organize and classify content. It can serve as legal proof of compliance to local and federal content regulations, and it drives application logic and business processes.
As developers began to build new applications, they increasingly looked for toolsets and platforms in the industry to assist with metadata creation and maintenance. The need for toolsets and platforms to build metadata-enabled applications marked the beginnings of Enterprise Content Management.
Let’s look at Use Case #1: disorganized content. One common scenario that leads to content disorganization is the deployment of multiple applications using different tables and databases. This scenario is depicted below.

In this example, the application developers create metadata
schemas in silos, without regard for a unified metadata approach that considers
the overall needs of the business. Applications developed in this fashion, over
time, lead to a fragmented, ad-hoc environment where workflows can’t be
automated, documents can’t be found, and audits fail.
The solutions that emerged as a result of this scenario fall
into two categories:
- Tools and processes to clean up this
environment. - Tools and processes to design applications
properly to avoid scenarios such as the one pictured above.
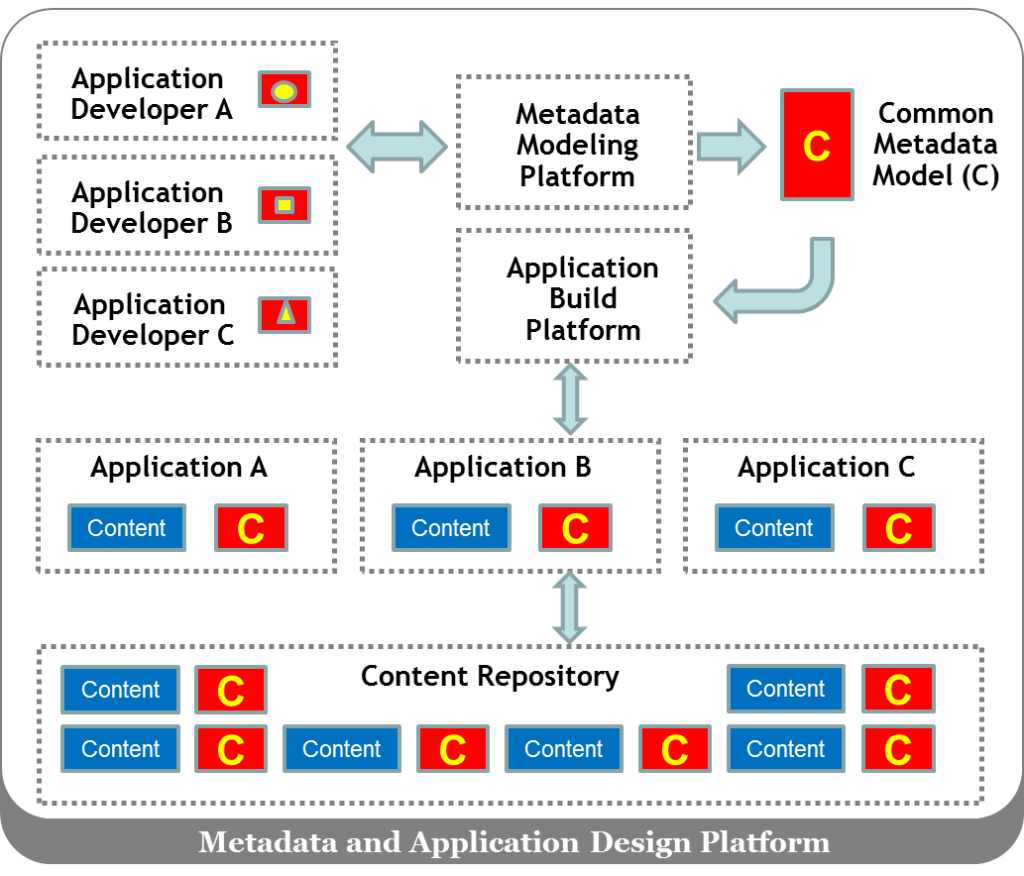
I’d like to start with the second solution. How can new applications be developed that
treat and manage metadata as a first-class citizen? The diagram below highlights one approach.

Using this approach, application developers feed the metadata
models of their individual applications into an enterprise-wide metadata modeling
tool. This results in a corporate metadata model that satisfies the needs of
the business. Once this model is approved, it is fed into an application build
platform, resulting in different applications that create different content.
The content, however, is associated with metadata that ties it into a larger
enterprise design. The final piece depicted above highlights the need for
applications to use an enterprise-wide content repository.
In future posts I will shed more light on the following aspects
of this solution:
- Metadata-modeling
tools - Application builders
- The content repository
Steve
EMC Fellow