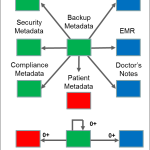
In a recent post I introduced the concept of infrastructure-based metadata and hybrid applications. Both of these areas represent the result of a new type of application workload in data centers: the hybrid metadata workload. This workload is depicted below.

Hybrid metadata apps sit above block, file, and object storage systems and read/write both (a) content, and (b) metadata about that content. In addition, they also read/write a third form of data: (c) infrastructure-based metadata. This type of metadata unites traditional application data with information about the underlying infrastructure. The diagram below draws a more detailed picture of this reality.

The diagram above leaves a question unanswered: where is the infrastructure-based metadata repository? The reality is that hybrid applications have a great number of choices about how to structure their infrastructure-based metadata and where to locate it.
One of the most innovative companies in the early days of this phenomena was Legato. Throughout the 1990s, Legato rode the evolution of the block, file, and object data storage systems. Their engineers created a wide variety of innovative new algorithms for backup and restore. In fact, many of these algorithms are still the bedrock of the backup and restore ecosystem over two decades later. When Legato technology was combined with block, file, and object storage systems, a surge of innovation resulted and new ways of thinking about backup emerged.
For example, consider how object-based storage systems altered the backup paradigm with Legato’s introduction of a technology known as DiskXtender (also referred to as DX).
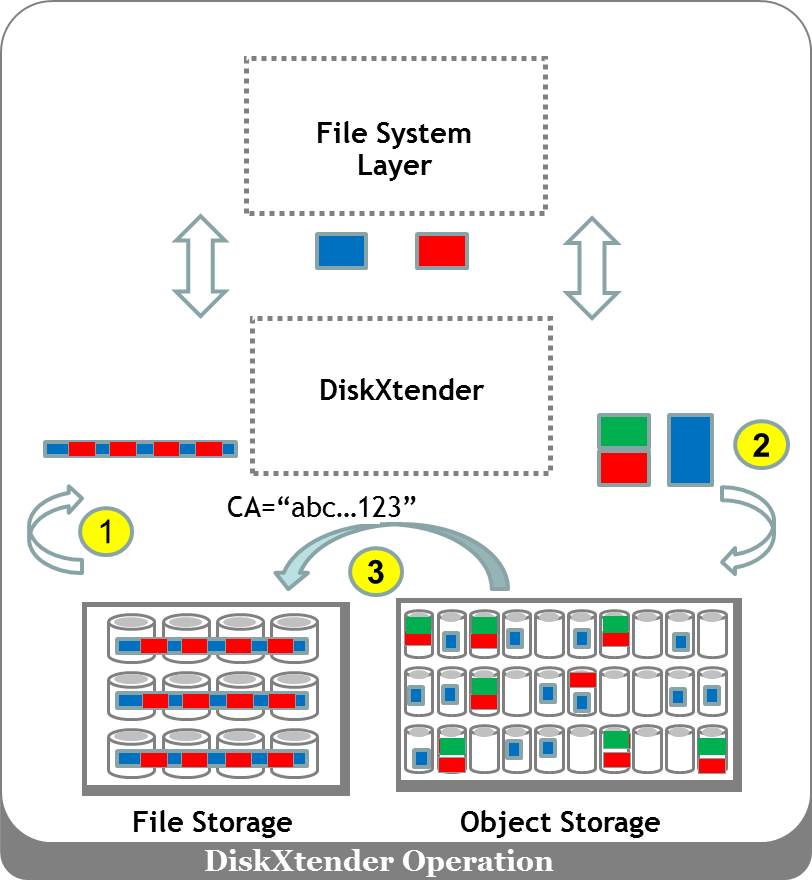
The diagram below shows DX algorithms inserting themselves into the application data path.

Before DiskXtender, the application would send workloads directly to a file storage device.
DX intelligently inserted itself into the data path to improve the protection of the data. It was able to “watch” every application request and determine which files were actively accessed and which files were “idle”. As “idle” files accumulated they caused full backups (e.g. on a weekly or monthly basis) to become virtually unusable. DX obviated the need to back up these files using the following algorithm:
- Reading the idle file (red) and its metadata (blue).
- Packaging the idle file and metadata as an object, and creating new, infrastructure-based metadata (green). The entire package was then offloaded to an object-based system.
- The resulting content address replaced the idle file and served as a pointer or bookmark to the true location.
This approach by DX offloaded file content to a cheap, reliable archive. Instead of performing a full backup of active and idle files, DX would backup active files and content addresses. This drastically reduced the backup window (often by 90-95%). If an application desired to open an idle file, DX would “follow the bread crumbs” to the object-based system and retrieve the content.
DX is a great example of a hybrid application workload. It proves yet again that application workloads are a true driver of evolution in the IT infrastructure. In this particular use case, infrastructure-based metadata (green) was stored onto an object-based system, which fundamentally changed backup and restore times in a positive way.
Furthermore, it laid the groundwork for many of the other
infrastructure-based hybrid backup optimizations driving the industry today
(e.g. VMware Changed Block Tracking, Windows Filter-Driver backups, and snapshot integration). I will explain the evolution of these technologies in a future post. Thanks to Stephen Manley and Mark Twomey for their continued contributions.
Steve
EMC Fellow