I’ve been writing a series of posts outlining an architecture that supports data valuation (assigning business/economic value to data).
I started with a description of the ideal architecture. In order to implement this architecture it would require making modifications to multiple layers within an existing data center (e.g. the PaaS, SDDC, and storage layers).
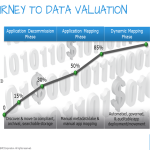
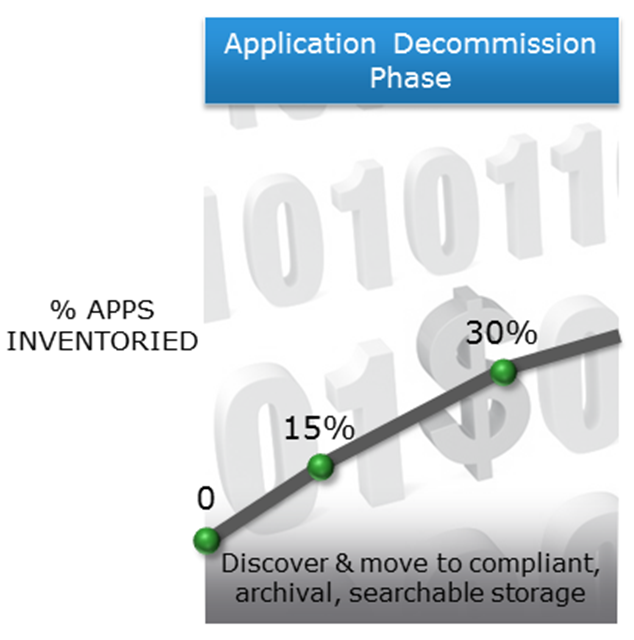
Instead of changing all of these layers at the same time I have been recommending a multi-step journey to data valuation that begins with application decommissioning. The key activity in this first phase is the execution of an application inventory. In particular the business would focus on applications that can be safely decommissioned. In many cases this number would represent 20-30% of an entire application portfolio. I use the diagram below to highlight this decommissioning process.

The second phase is a logical continuation of the first. The application and infrastructure teams continue to parse and process the output from the application inventory tool (e.g. Adaptivity). Once all of the candidate applications (approximately 1/3) have been decommissioned to compliant, archival, and/or searchable storage, the next phase is to manually map additional applications onto the right level of trusted infrastructure. This activity is augmented by updating the Metadata Lake inventory created in phase 1. The diagram below highlights this activity.

This manual process is quite similar to many of the recommendations made about application decommissioning:
The team in charge of the migration should manually record any statements made about the business value of the data (e.g. data policies), combine that information with the capabilities of the InfoArchive infrastructure (trust services), and store both of them into a Metadata Lake.
Instead of moving applications to an archival platform like InfoArchive (phase 1), during phase 2 the applications are either enhanced to run on a more trusted private infrastructure or moved to a cloud-based architecture. Either one of these decisions is a common output for tools like Adaptivity. As a result an increasing percentage of “policy-to-infrastructure” application mappings is being recorded during the inventory process. As this percentage moves closer to 70-80% of the overall portfolio, the application and infrastructure teams are beginning to create a cadence and deeper understanding of articulating data value and resulting infrastructure placement.
This understanding can then be leveraged to move to the third stage of the Journey to Data Value: the Dynamic Mapping phase.
I will introduce the Dynamic Mapping phase in a future post.
Steve
EMC Fellow