In a recent post I introduced the concept of “infrastructure-based metadata”. In a data center, this type of metadata falls into four categories:
- Metadata about configuration management of the infrastructure.
- Metadata relating to data center security.
- Metadata that facilitates data center backup and recovery.
- Metadata that facilitates content management activity.
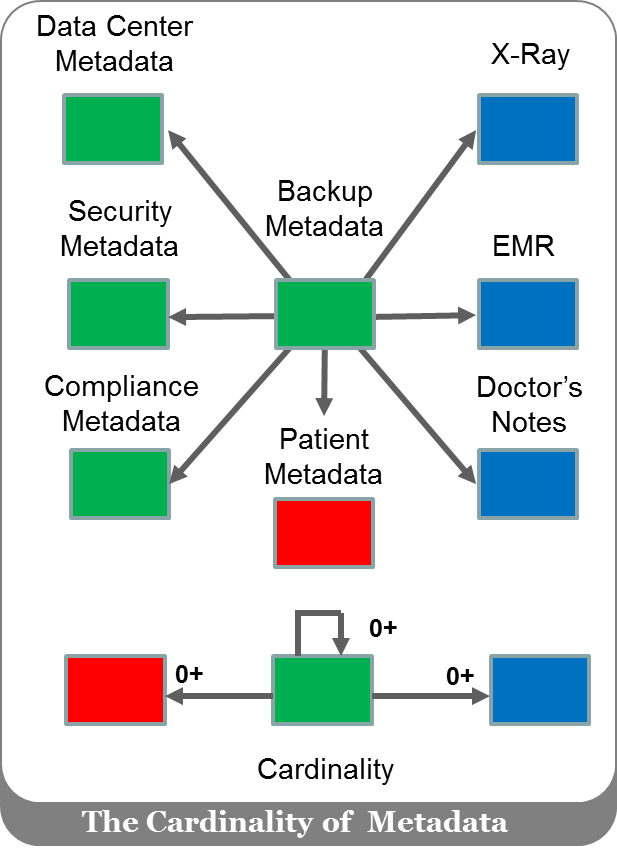
I also mentioned that this type of metadata has complex relationships (cardinality) with other forms of (a) infrastructure-based metadata, (b) application content, and (c) metadata describing application content. I used the following diagram to highlight this cardinality in the context of backup and recovery metadata.

Application workloads were sending a continual stream of content (blue) and metadata (red) to block, file, and object storage systems. As more and more disparate storage systems were deployed within data centers, the amount of intrastructure-based metadata (green) began to rise exponentially.
A new wave of application workloads began to emerge, and these workloads were primarily focused around the centrality of infrastructure-based metadata. New workloads lead to new innovations, and perhaps one of the first (and toughest) problems to solve was to help customers backup and recover the data associated with their workloads.
The need for new applications for managing backup and recovery was characterized by several fundamental problems:
- The metadata catalogue itself. How is the infrastructure-based metadata
for backup and recovery stored? Where are all the copies (and versions) of the
content? Who can access the copies and versions? The catalogue has always
been the core of any backup application. To meet the increased scale (trillions
of objects) and scope (search across multiple layers of metadata), backup
applications must evolve their core. - Complex data center configurations. Traditionally, backup clients generated and
sent the metadata to the catalogue. As data scaled, customers turned to new
protection mechanisms for better performance. This created new paths between
the primary and secondary (the backup) systems. With so many permutations and
paths between block, NAS, and CAS storage systems, how can the backup application
discover and ingest the metadata into its catalogue?
Solutions to these problems would bring what my EMC colleague Stephen Manley calls a “metadata ethos” to the IT industry. The fast and reliable storage of content became table stakes for enterprise customers; the real action (and business profit) would revolve around the adoption of effective tools and processes for handling infrastructure-based metadata.
In my next post I will describe how the metadata ethos resulted in considerable backup and restore innovation across NAS and CAS systems.
Steve
EMC Fellow