When it comes to securing content in the cloud, section 7.2 of the AWS Customer Agreement currently says the following (in part):
We strongly encourage you, where available and appropriate, to (a) use encryption technology to protect Your Content from unauthorized access, (b) routinely archive Your Content, and (c) keep your Applications or any software that you use or run with our Services current with the latest security patches or updates. We will have no liability to you for any unauthorized access or use, corruption, deletion, destruction or loss of any of Your Content or Applications.
The encouragement to use encryption technology is something I can understand if my application sits outside of the cloud and I am sending files back and forth. On top of encryption there are other techniques that can be used to detect “corruption”.
But what about database queries? When a query is sent into a cloud and a result comes back, how can we know that it’s correct?
Trustworthy Outsourced Computations
I listened in on a lecture today given by Nikos Triandopoulos of Boston University. He visited EMC Cambridge as part of the monthly lectures sponsored by the EMC Research Cambridge Lecture Series.
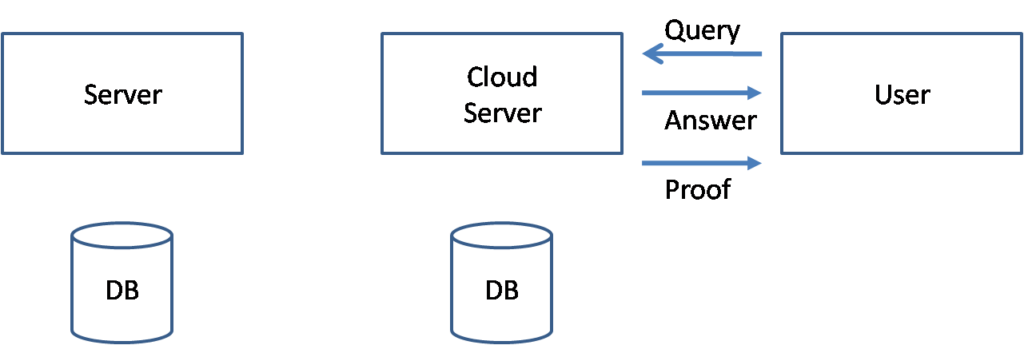
Nikos introduced his topic by highlighting that cloud has inserted itself in between users and their trusted databases. When a database query enters a cloud it can have any number of “proxy” hardware and software entities that pass data back and forth. His research is trying to solve two problems:
- How can a user verify the “correctness” of a query result? How can the user be sure that malicious software did not intercept the query and return a bogus answer?
- How can this be done efficiently (e.g. performance optimized)?
At a very high level this research is attempting to do the following:

When a user submits a database query into the cloud, a cloud server will typically intercept and pass it on to the “true” database server that stores the actual database. The diagram above highlights that when a query result is returned to a user, it is accompanied by additional metadata that is labeled “proof”. This metadata allows the user to determine whether or not the query is correct or not.
That’s heady stuff, and the implementation is more than I can communicate in one blog post. But here is the gist of how something like this can be implemented.
First of all, the entire database has a hash function run against it, which results in a top-level “digest”.
The same hash function is applied against pairs of adjacent database entries, resulting in a “digest-per-pair”.
This hash function is then recursively applied against sets of adjacent pairs until the complete representation forms a Merkle tree, with the top-level digest at the top.
When a query result is returned, nodes in the Merkle tree are also returned, and the user can perform a mathematical calculation using the query result, the nodes, and the overall top-level digest.
Sound like a lot of work? What about database updates? Isn’t it slow? The rest of Nikos’ lecture touched on many of these questions.
As I listened on the phone I could hear a lot of questions being asked, and I recognized the voices of my RSA co-workers. Encryption and correctness of database operations is right up their alley, and it will be interesting to see if future product roll-outs will leverage these ideas.
Steve
http://stevetodd.typepad.com
Twitter: @SteveTodd
EMC Intrapreneur

I’m glad you brought this up. The massive scale of cloud storage operations makes errors much more likely. Hashing the database is interesting, but what about integrity checks on the data? How many systems do proactive data integrity checks?
Steve – I guess it depends on what you mean by “systems”. Storage Systems like V-Max or CX do their own internal “scrubbing”. Centera systems do the same for objects. These are different form of proactive data integrity implemented inside EMC systems.
Does Atmos do the kind of database hashing described above? And does it also do proactive hashing and repairing (aka scrubbing) of data?
Steve, Atmos doesn’t have a SQL-like database interface for customers, so the answer to your first question is no. For your second question, DaveG tells me that consistency checking of objects/meta are part of the Atmos product.
Get Cloudquery domain name before Yahoo does.
Yahoo”s purchase of Xoopit cloudquery may have well burried that Xoopit part of the name….But Cloud Query lives forever. “Cloud Query” is essentially associated to Cloud Computing as strongly as Google to “search” engine. People will indeed forget Xoopit but they will continue to “Query” the cloud as long as cloud computing exists. Here is an extract of Thinking out Coud blog:July 22, 2009
“Yahoo-Xoopit Acquisition: A Missed Opportunity?
Earlier today I published a blog post on GigaOm about the Yahoo-Xoopit acquisition and what I think is an overlooked aspect of the deal, especially as it related to Xoopit’s CloudQuery service. Check it out: Will Yahoo Use Xoopit’s CloudQuery to Help Usher in the Real-Time Web?”
Well…to me the missed opportunity was Xoopit’s failed(low offer for CloudQuery.com prior to the sale to Yahoo and Yahoo not getting the domain name prior to the deal with xoopit.
This is a real chance to make their failure OUR OPPORTUNITY.
http://flippa.com/auctions/98739/Yhaoo-acquired-Xoopit-CloudQuery-for-20-Millions-but-not-the-GENERIC-domain-name