When the acronym RAID came out, it stuck like glue. The original paper from Berkeley was extremely influential in its introduction of terminology that combined disk striping and data protection algorithms. The influence of that original paper was carried over to RAIN as well.
When the RAID paper came out there was already a set of researchers and industry types ruminating over parallelizing disk access while still being able to handle faults. Patterson and team formalized some base level terms that reflected those discussions.
The term “RAID” is in its third decade.
In 2009 we’ve had researchers and industry types having analogous conversations about storage challenges in a virtualized data center.
Will the same type of widely-adopted acronym surface?
It’s an interesting exercise to revisit the industry context for the original RAID paper. Here’s a drawing that describes the mid-80s setting for RAID:

CPU speeds were increasing faster than disk speeds. CPUs were hanging around idle while disks were (slowly) processing their queue. RAID defined a lexicon for striping data across multiple disks in order to improve performance. It also defined redundancy schemes to guard against the increased chance of disk failure.
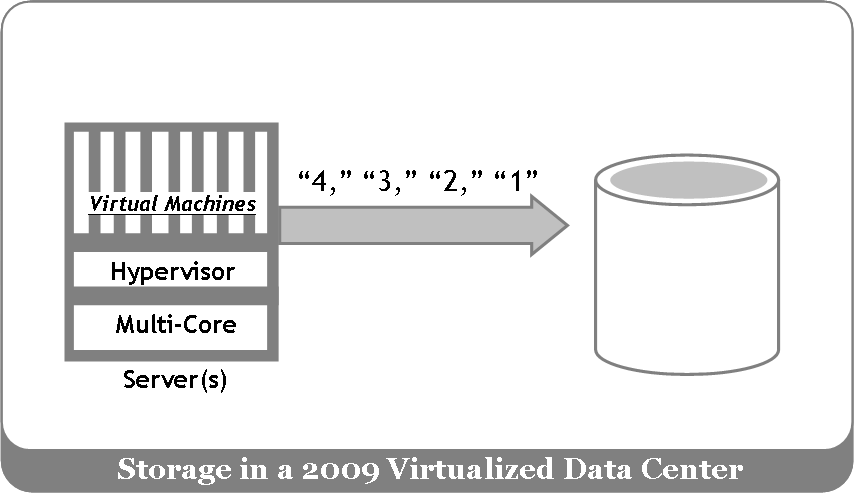
If I were to draw an overly simple but analogous picture highlighting the virtualized data center challenges for 2009, it might look something like this:

In the mid-1980s the storage problems solved by RAID addressed performance and data integrity/availability.
In 2009 we are seeing multiple cores, massively virtualized servers, mixed workloads, and massive amounts of data. Performance and data integrity are clearly still issues, but other discussions are in the mix as well (e.g. storage scalability and manageability).
Academia and industry technologists are having conversations about these problems. Solutions have been rolled out, and new ones are being proposed.
Do you think we’ll see a treatise similar in scope to the original RAID paper?
Steve
http://stevetodd.typepad.com
Twitter: @SteveTodd
EMC Intrapreneur

Steve
The physical disk architecture is clearly a pain. The sequential nature of reading and writing data (as you are well aware) is a bottleneck. So, how can you get more I/O in and out of spinning disks?
I guess one option is to not have HDD at all and use SSD. Another could be to consider the following; physical disk partitioning. For disks with multiple platters, make the read-write heads independent and read them using separate I/O pipelines and interfaces. As we get to 1/2/3TB drives, make them logically multiple (say) 500GB drives. Of course the argument against will be cost….
Good thoughts Chris. Perhaps my diagram of 2009 storage should not have a cylindrical disk because it implies HDD! As you point out, SSD plays a major role. For now we can just consider it a generic icon that represents persistent storage.
Interesting thought about multiple platters / independent heads. But you haven’t given that concept a name or an acronym that relates to the challenges of storage in a virtualized environment. I’d be interested to hear what you’d come up with.
I think it could be argued that Eric Brewer’s CAP presentation (http://www.cs.berkeley.edu/~brewer/cs262b-2004/PODC-keynote.pdf) is the RAID paper for a lot of work going on in cloud storage right now.
Jeff – although Brewer’s presentation is nearly 10 years old, when you look at the 2nd to last slide (New Hard Problems), you can see a preview of some of the problems facing storage in a highly virtualized environment.