In a recent post I took a look at Insurance and Data Value. The data insurance topic is part of a larger Architecting for Data Value research project that I have been working on with Dr. Jim Short at the San Diego Supercomputer Center. The research is designed to help the industry grow towards new organizational models, business processes, and IT infrastructures that are related to calculating the economic or business value of data.
In April I suggested an approach for migrating towards an automated valuation framework. This framework would provide the ability for an IT organization to automatically place and relocate applications based on business value.
This type of framework requires moving towards an architecture that is self-aware in terms of trust capabilities. If a data insurance company were to respond to a request for insurance, this new framework would generate an automated report that would give a data set underwriter many of the things they would need to understand the risks involved in insuring the data.
Over the summer the industry moved closer to this vision with the results published by RSA’s Cybersecurity Poverty Index Assessment:
The Cybersecurity Poverty Index is the result of an annual maturity self-assessment completed by organizations of all sizes, industries, and geographies across the globe. The assessment was created using the NIST Cybersecurity Framework (CSF). The 2015 assessment was completed by more than 400 security professionals across 61 countries.
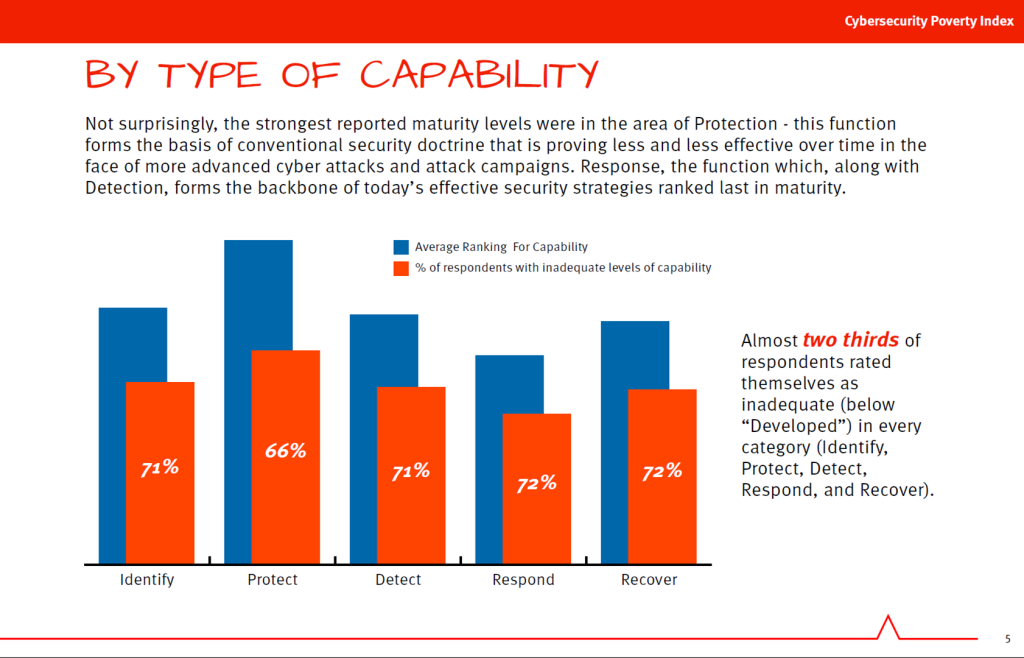
The maturity assessment is a self-rating on an organization’s capabilities in the 5 key areas outlined by the CSF: Identify, Protect, Detect, Respond, and Recover. The primary conclusion reached by the survey is as follows:
The biggest weakness of surveyed organizations is the ability to measure, assess and mitigate cybersecurity risk, which makes it difficult or impossible to prioritize security activity and investment.
One area that I found most interesting (in terms of data insurance) is the following result:

What would occur if this type of graph, which contains a ranking of the 5 CSF categories, were provided to a cyber-insurance underwriter? This would give the underwriter a much better basis for underwriting the protection capabilities of the insured (better than most of the manual forms being used today during the process).
RSA’s Archer product is already being used today to generate this type of data during the cyber-insurance application process.
In the future, I am certain that Archer can be uses to call APIs that gather trust capabilities directly from the infrastructure, further streamlining the data insurance application process.
If you are interested in keeping an eye on this space, I highly recommend starting out by watching the explanations of the Cyber-security poverty index on this site.
Steve
EMC Fellow

