Data consolidation into a single data store can have analytic advantages; a broad range of data sources can be accessed in one place.
Data consolidation can also yield governance advantages; compliance to regulations can be easier when reducing the number of management points.
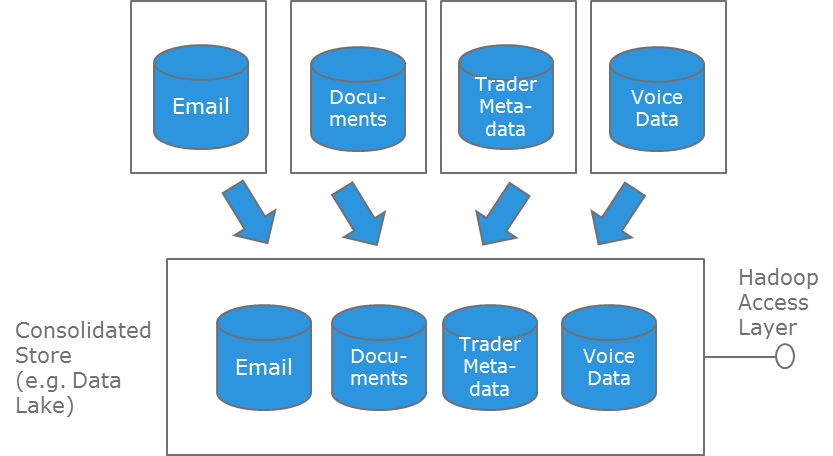
The analytic and governance advantages of data consolidation often stand opposed to one another, however. In order to illustrate this dilemma I’d like to use an example from the financial sector. Consider the diagram below in which silos of data are moved into a consolidated store that has Hadoop capabilities (e.g. a Data Lake).

In the financial industry, multiple data sets may have the same set of regulations associated with them. Emails containing trading discussions, internal memos, metadata about specific individual traders (e.g. what country they sit in) may need to have the same retention policy associated with them. Applying a single hold over associated data of different types is much harder if the data lives in silos compared to a centralized archive. Once this is implemented, a logical next step would be to gain new business insights via consolidated analytics.
The desire to use analytic tools like Hadoop, however, can undermine those policies and severely restrict the analytic benefits of data consolidation. While Hadoop does have security capabilities, these capabilities are often blind when it comes to the governance policies that are in place. Running Map/Reduce jobs in this type of environment can unknowingly violate regulations that can cost a corporation hundreds of millions of dollars. Last year Reuters reported the staggering amount of penalties that are being paid by some of the world’s largest banks:
Twenty of the world’s biggest banks paid more than $235 billion in fines. Interactive graphic: http://t.co/9D2BMErvzI pic.twitter.com/9cm1AeBC5v
— Reuters Top News (@Reuters) May 22, 2015
One industry solution that has emerged to solve this problem is InfoArchive. I’ve written before about InfoArchive in the context of application decommissioning. It is a platform that is certainly used often for rationalizing an application portfolio as a cost reduction play.
In this post, however, I’d like to take a closer look at the use InfoArchive for data consolidation with (a) simplified, centralized governance that (b) maintains full compliance in the face of analytics that are restricted by such regulations.
The ingest function of InfoArchive leverages Apache Storm on the front end. This serves a variety of purposes, including correlation across disparate data sources, linking data, enabling query across all sources, applying (potentially thousands) of retention policies (based on geography), and enforcing role-based authentication. These capabilities are a clear argument for centralized compliance enforcement (instead of attempting to enforce across disparate silos).
No matter what operation tries to access the data (e.g. a query or a read operation) the InfoArchive policy engine enforces the same policies against any operation.
On top of this framework Hadoop capabilities are available. InfoArchive supports HDFS and Map/Reduce Jobs. InfoArchive is actiing as a Hadoop File System via a driver-based model. For example:
- If Hadoop attempts to read data that can only be exposed in encrypted form, InfoArchive performs field-level encryption as part of the operation.
- If Hadoop attempts to access a field that has a masking policy, the data returned to Hadoop will be masked (e.g. asterisks replace the actual characters for specific fields in the data set)
These two features, when combined with the other security and compliance features mentioned above (role-based authentication, linking/correlating, etc) can guard against the dangerous use case of a data scientist that says “just give me all the data”, receives everything from Hadoop, and violates any number of regulations.
InfoArchive also has a feature that can be used when a data scientist legitimately exports a data set with a transformation. It keeps track of the relationship between the original source and the modified copy and keeps a pointer to that copy. If there is a destroy workflow for that data, InfoArchive can attempt to delete the modified rendition as well, and notify an administrator if that’s not possible.
I’ve not seen equivalent functionality in other Hadoop distributions, have you? I’d love to gather some thoughts on this via the comment section below.
Steve
Twitter: @SteveTodd
EMC Fellow

