I’m in the Bay Area today and was faced with a tough choice. Do I go to the opening day of RSA Conference, or do I attend the Pivotal HD 2.0 launch?
So many new features, so little time.
Today’s Pivotal HD 2.0 release is more evidence of the continued march towards analytic correctness. In a previous blog post I laid out the foundation of the argument: more data variety yields better (more accurate) analytic results. Of course, the speed at which the analytics run is also important, which is why Pivotal’s massive parallel processing approach (moving the analytic algorithms closer to the data) has bucked the trend of buying beefy servers to run analytics.
The emergence of the Hadoop software framework has enabled the ingest of a wide variety of unstructured data. This makes Hadoop a perfect framework for implementing “analytic correctness”. Big Data applications now have a huge repository for unstructured content that can be queried/analyzed using a parallel approach.
Hadoop, however, has also been disruptive from a toolset perspective: most enterprise customers have made a large investment in SQL skillsets and tools. This expertise cannot simply be re-purposed to an all-Hadoop framework; the majority of legacy corporate value still lies embedded in row-column, structured formats.
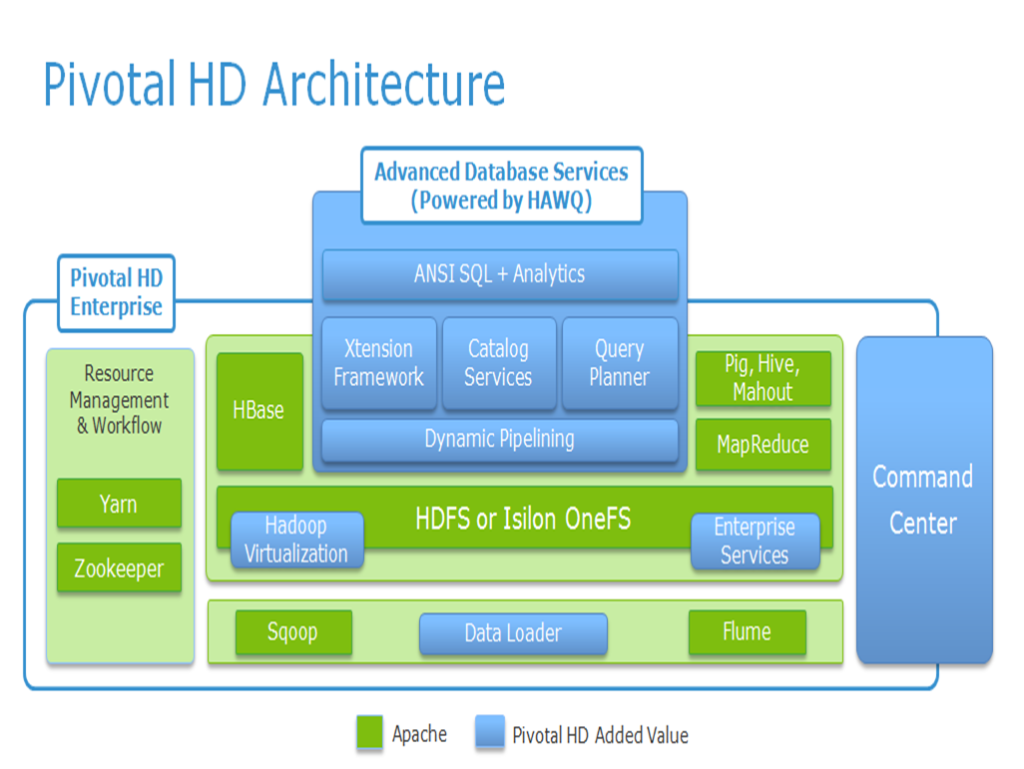
Running one analytic model against both structured and unstructured data requires a unified toolset. I like Pivotal’s approach to the problem, which is depicted below:

This diagram shows an ANSI SQL path that leverages new “HAWQ” functionality. HAWQ has evolved from the original Greenplum SQL engine (optimized for parallel execution over the last 10 years). The real story, however, is the integration with Hadoop under the covers. The integration allows enterprise customers to continue leveraging their SQL tools and skillsets, while blending the integration of structured and unstructured analysis.
In addition to blended analytics and speed, Pivotal HD is based on the open-source Apache Hadoop framework. Many of the additions made by the Pivotal team have focused on hardening the platform (e.g. making it robust enough for enterprise use). The diagram above gives a good understanding of what Pivotal has added on top of the Apache framework.
It’s a triple play of features being announced today:
- Blended unstructured/structured analytic capability
- Speed (massively parallel processing)
- High quality
These three things will provide a framework for further innovation down the road, which I hope to cover in future posts.
Steve
Twitter: @SteveTodd
EMC Fellow