I started writing about application workloads and innovation by using a simple diagram:

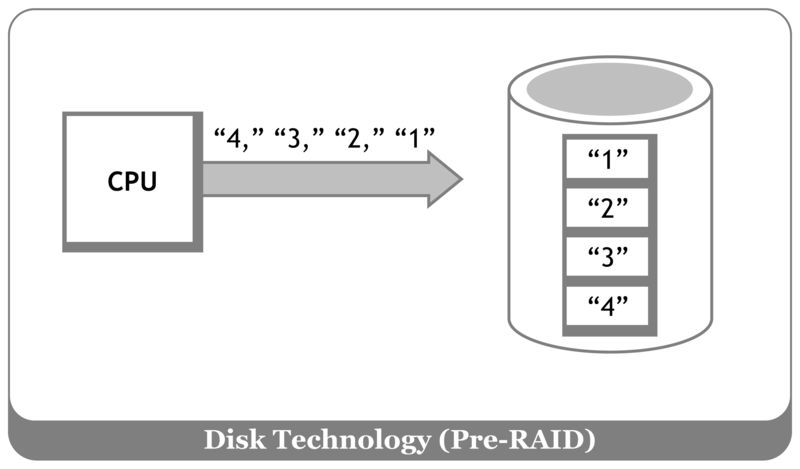
Applications want to store and retrieve data. In the pre-disk array era, the binding between an application (compiled to run directly on a CPU) and the application storage (sitting a couple of feet away on a flat-ribbon SCSI bus) was simpler to describe.
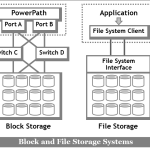
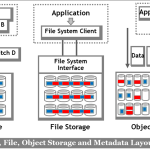
As workload complexity increased, applications began to utilize three very different forms of storage interfaces: block, file, and object. This in turn led to the deployment of different storage architectures within the data center: SAN, NAS, and CAS. Each of these three architectures internally organized application metadata in different ways:

The diagram above illustrates the introduction of “metadata awareness” within modern storage systems. Applications were generating increasing amounts of both content and metadata, and data center operators often deployed all three approaches to satisfy workload demand.
The pace of metadata growth did not slow down. Applications began generating new forms of expanded metadata. These new forms can be grouped into two categories.
- Metadata driven by new types of applications
- Metadata driven by the infrastructure itself in areas such as efficiency, compliance, and security.
My company (EMC) innovated heavily in both of these areas during the previous decade. For the second item (metadata related to infrastructure), the necessary skillsets to innovate were not always found within the company itself (e.g. enterprise storage experts are not necessarily security or backup experts). This resulted in an “innovation by acquisition” strategy in many cases, as evidenced by the diagram below.

In my next post I will take a deeper look at infrastructure-based metadata ramifications that caused innovation in the high-tech industry.
Thanks again to Stephen Manley for his historical insights into these industry trends.
Steve
EMC Fellow