 Over the last several weeks I’ve been establishing a foundational set of building blocks for a new form of IT infrastructure. This infrastructure is well-suited to run new forms of analytic, mobile, and social business applications.
Over the last several weeks I’ve been establishing a foundational set of building blocks for a new form of IT infrastructure. This infrastructure is well-suited to run new forms of analytic, mobile, and social business applications.
In this post I’d like to describe the final building block: the container within which these new applications are developed and deployed. Before getting there, let me review the layers of building blocks that have been discussed so far:
- HDFS is a foundational part of the new infrastructure, but it should be layered underneath an in-memory data grid (IMDG) as an enabler for a data lake architecture. While the architecture seems simple (HDFS + IMDG), the issues associated with creating a true data lake are anything but simple.
- In-memory data grids are a part of the industry trend towards server-based storage. Deploying storage at the server tier has ramifications that should be understood before massive scaling of the new infrastructure begins.
- Understanding the balance and issues associated with deploying server-based storage alongside an HDD-based tier will be another critical deployment decision.
- Given the massive capacity sizes for a data lake architecture, a secure storage tiering strategy to a storage cloud service provider will provide an option to minimize (or eliminate) HDD deployment in a private environment.
- Storage catalogues will be used for managing the storage infrastructure.
- Data provisioning and data protection APIs will be converged in order to minimize data movement during protection operations.
- A cloud orchestration platform will be deployed that can automatically map/monitor workloads to/within infrastructure via mathematical techniques. This capability will be the signature achievement of a software-defined data center (SDDC).
The point of this entire exercise is to characterize a next generation infrastructure to run new applications.
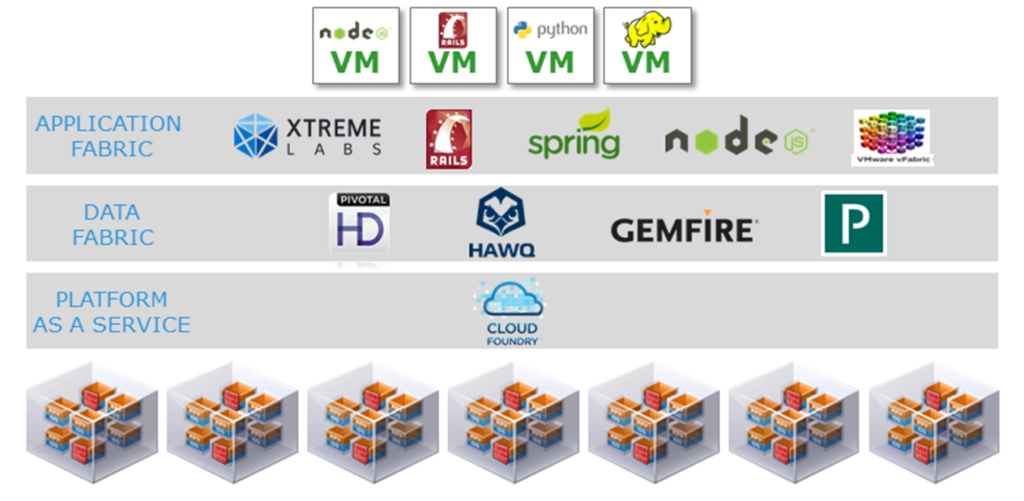
What type of infrastructure is required to deploy on top of an SDDC? As I’ve mentioned previously, the Pivotal framework provides a 3-layer solution to make deployment (and rapid development) happen.

The key benefit that this architecture enables is coding and deployment speed for applications. This speed is realized by combining the benefits of the three layers:
- CloudFoundry abstracts the developer away from the underlying cloud infrastructure. Developers write their code to a set of services and avoid any reference to specific infrastructure. This saves time by removing responsibility for creating infrastructure-specific code.
- The Data Fabric contains a set of services that put data access at the fingertips of the developers. If the developers favor map/reduce, they can use PivotalHD. For SQL they use HAWQ, and for fast, real-time analytics they use GemFire. The data fabric also contains the Pivotal Analytics toolset for data exploration (via a GUI) as well as data ingest functions (e.g. schema recognition).
- The application fabric contains all of the agile tools needed to write software quickly. As I mentioned previously, Spring plays a key role in providing re-usable components to developers, which facilitates coding speed.
The Pivotal approach (and the SDDC constructs underneath it) make a great deal of sense for the creation and deployment of next generation data analytic applications.
What other forms of applications are suitable to run on this platform? The Spring framework has capabilities for social, mobile, etc. In a future post I will dive more deeply into Spring, as well as discuss how to integrate mobile devices into this third platform architecture.
In the meantime, this brings the 3rd platform infrastructure discussion up to the application layer. This unerstanding will facilitate future posts on interoperability between the two infrastructures listed below.

Steve
EMC Fellow